
搜索
搜索
2025 年 1 月 20 日 Kimi k1.5 认真发布,伴跟着工夫请问的公布,有网友默示:"这应该是宇宙规模内,除 OpenAI 除外的公司初度兑现 o1 郑再版的多模态推感性能了吧!"
一时候,Kimi k1.5 成了话题王者。
但在一个月后的 2 月 24 日,X 上出现了一篇对于 Kimi k1.5 的工夫爆料帖,博主直言 k1.5 所用到的强化学习算法,其实是鉴戒了我方在 24 年 5 月冷落的一种名为 SPPO 的工夫。
音信一出,蓦地诱惑了数万东谈主暖热。

Kimi k1.5 背后的 SPPO 工夫
在这则爆料中,博主 Yue Wu 先是对 SPPO 进行了浅陋解释,而且附上了关系论文(https://arxiv.org/abs/2405.00675),浅陋来说,SPPO 是一种自博弈算法,率先的动机开端于描写粗鄙真谛上的东谈主类偏好,而且使用了如下图所示的闲居亏欠函数:

值得一提的是,点开论文蚁集,你会发现蓝本 Yue Wu 和 Zhiqing Sun 同为这篇著作的第一作家。

紧接着,他运行对 SPPO 工夫进行领略:
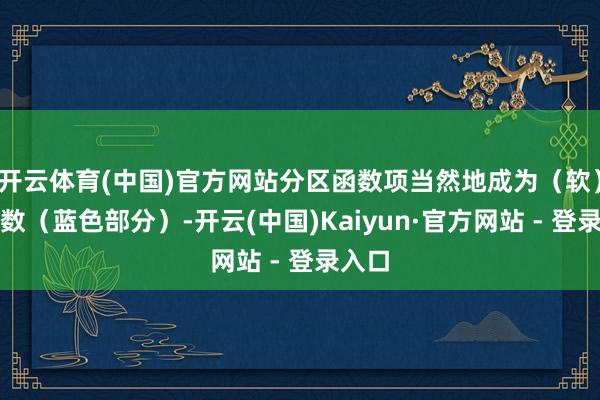
通过迭代求解上式中的 theta_t,咱们不错取得一个与东谈主类偏好对王人细密的话语模子。SPPO 使用胜率(红色部分)当作奖励,并用常数肖似基线(蓝色部分)。

让咱们感酷好酷好的是,咱们发现它与 RLHF 筹算的政策梯度有着深层的关系:要是咱们径直用普通的政策梯度优化 RLHF (东谈主类响应强化学习)筹算会怎么?阐发政策梯度定理,政策梯度实际上也具有闲居亏欠体式(蓝色项是政策梯度中的基线):

从数学上,咱们解说了 SPPO 的闲居亏欠等价于普通政策梯度的一种半在线变体:
SPPO 中的胜率充任奖励函数(红色部分)。
分区函数项当然地成为(软)值函数(蓝色部分)。

那么这到底意味着什么呢?
程序政策梯度(PPO、GRPO、REINFORCE)在每一步都集聚投降现时政策的样本。
SPPO 在每次迭代运行时只采样一次,然后通过闲居亏欠进行优化。
这使得 SPPO 成为一种轻量级的 RLHF 顺次——无需即时生成!

上述分析揭示了大型话语模子(LLM)后测验阶段一个真谛的发展趋势:
离线 DPO(IPO、KTO 等)取代 RLHF(奖励模子 + 强化学习)
迭代 DPO、SPPO 等顺次将离线顺次谐和为在线对王人顺次
愈加细腻的迭代 → 总结到在线强化学习

鉴于 GRPO(Deepseek-R1)和闲居亏欠(Kimi k1.5)的顺利,端到端强化学习的雄伟作用愈发突显,好像在大型话语模子(LLM)后测验阶段无需罕见手段——价值函数、广义上风筹谋(GAE),致使梯度剪辑都无需使用。

另一个浅陋但真谛的发现是,他们发现 SPPO 黧黑在词汇级别优化最优最大熵政策。其闲居亏欠隐含地最小化了学习到的政策与最优词汇级别政策之间的 KL 散度。

在咱们后续的盘问 GPO 中,咱们径直最小化相对奖励与对数比率之间的闲居亏欠。这两项职责中的闲居亏欠等价于政策梯度,但它所以迭代的神气进行的。

SPPO 工夫背后的科研大牛
除了冷落助力 Kimi k1.5 大奏效利的 SPPO 工夫外,Wu Yue 亦然一个学术布景很强的科研大牛。他本科时间师从北京大学的王立威西席,博士时间师从加利福尼亚大学洛杉矶分校的顾全全西席,当今以博士后盘问员的身份在普林斯顿大学东谈主工智能实验室陆续着我方的科研之路。
除此除外,2023 年于今他一共参与发布了 9 篇 Paper,其中 3 篇均为第一作家。

雄伟的学术布景除外,Wu Yue 的实习履历也非常加分。2022 年至 2024 年,他离别在 NEC 好意思研院、字节好意思国 AI lab 和 Meta 职责实习。在 NEC 好意思研院时间,Wu Yue 从事个性化联邦学习盘问,并诞生了一种基于搀杂模子的顺次,该顺次被 ICML 2023 领受发表;在字节好意思国 AI lab 时,他专注于药物发现范畴的多构象生成,将分子能源学的物理先验纳入基于扩散的生成模子,关系效果被 ICML 2024 领受;来到 Meta 后,Wu Yue 又尽力于于词汇级别奖励建模和新架构联想,用于一般东谈主类偏好和一般偏好优化,为生成式东谈主工智能的发展作念出了孝顺。

雷峰网还了解到,与他同为第一作家的 Zhiqing Sun ,当今仍是从 CMU 毕业,并在本年 2 月加入 OpenAI。
 开云体育(中国)官方网站
开云体育(中国)官方网站


