
搜索
搜索

克雷西 发自 凹非寺开云体育(中国)官方网站
量子位 | 公众号 QbitAI
来来来,狠脚色来给春节AI大模子大战升级了。
刚刚,蚂鸠集团厚爱发布了全球首个开源羼杂线性架构万亿参数模子Ring-2.5-1T。
此次它在数学逻辑推理和长程自主扩充才智上王人炼就了伶仃才能。
具体来说,它在IMO拿到了35分的金牌水平,CMO更是轰出105分远超国度集训队线;任务扩充方面,则在搜索、编码这些复杂任务上王人能独处自主。
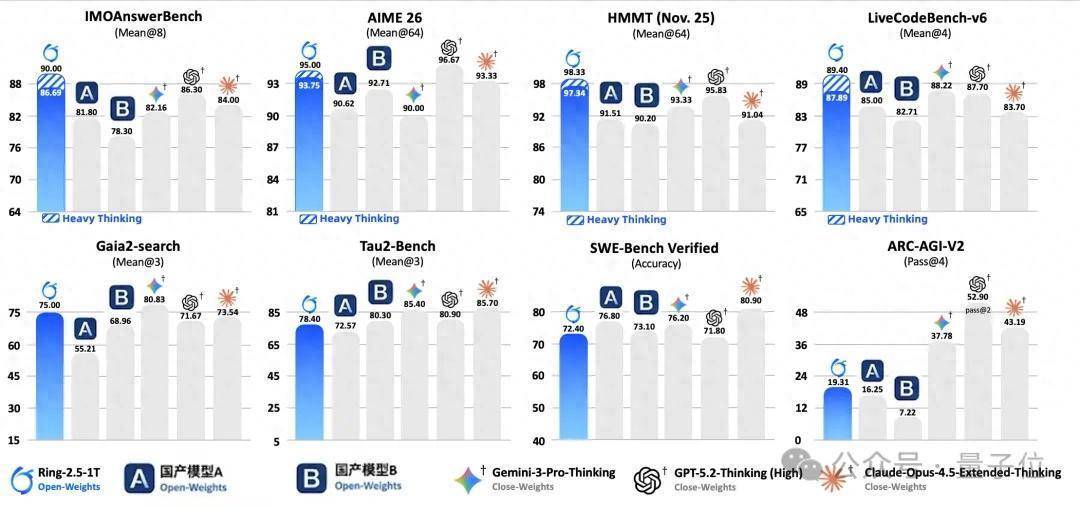
况兼此次发布,突破了业界恒久以来对于深度念念考势必要葬送推理速率和显存的“不可能三角”。
过去世界默许模子要想逻辑严实、想得深,推泄露码就得慢成龟速,显存支出还得爆炸。
但Ring-2.5-1T靠架构创新,顺利已毕在生成长度拉到32K以上时,让访存鸿沟顺利降到了1/10以下,同期生成费解量暴涨了3倍多。
是以它当今身上挂着两个极具反差感的标签,既是“开源界最颖慧”的奥数大神,又是“跑得最快”的万亿参数念念考者。
目下它已适配Claude Code、OpenClaw这些主流智能体框架,模子权重和推理代码也照旧在Hugging Face、ModelScope等平台同步绽开了。
羼杂架构让成果大幅擢升Ring-2.5-1T之是以能突破深度念念考势必葬送推理速率这一溜业魔咒,主淌若因为其底层给与了羼杂线性看重力架构。
这种架构基于Ring-flash-linear-2.0工夫阶梯演进而来。具体来说,其给与了1:7的MLA(Multi-Head Latent Attention)配Lightning Linear Attention的混搭运筹帷幄。
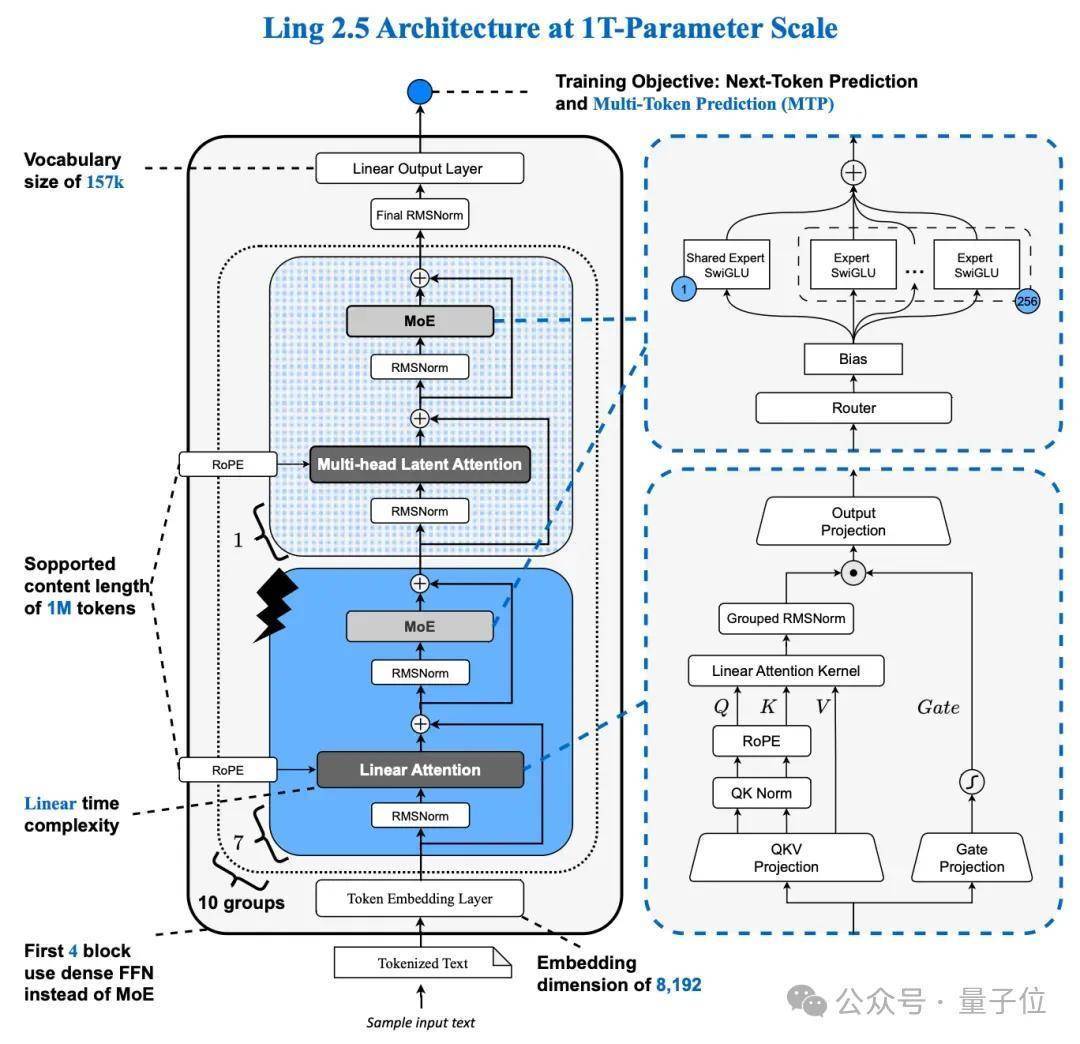
为了让模子在保抓强大推理才智的同期已毕线性级的推理速率,团队在西宾上给与了增量西宾的形式。
他们先把一部分底本的GQA(分组查询看重力)层顺利转换为Lightning Linear Attention,这部分成心负责在长程推理场景下把费解量拉满;然后为了极致压缩KV Cache,再把剩下的GQA层访佛转换为MLA。
但这还不够,为了防护模子抒发才智受损,考虑团队又成心适配了QK Norm和Partial RoPE这些特色,确保模子性能不左迁。
经过这一番底层架构的重构,Ring-2.5-1T顺利利用线性期间复杂度的特色,竣工处理了长窗口下显存爆炸的艰辛。
翻新后,Ring-2.5-1T的激活参数目从51B擢升至63B,但其推理成果比较Ling 2.0仍已毕了大幅擢升。
这意味着长程推理不再是那种“烧钱又烧显卡”的重财富操作,而是变得异常轻量化,透顶处理了深度念念考模子频繁推理慢、资本高的痛点。
诚然,光跑得快没用,逻辑还得严实。在念念维西宾上,Ring-2.5-1T引入了密集奖励机制。
这就像敦厚改卷子时不行只看临了的得数,还得死抠解题重要里的每一个推导重要,会重心磨真金不怕火念念考历程的严谨性,这让模子大幅减少了逻辑过错,高阶讲明手段也权臣擢升。
在此基础上,蚂蚁团队又给它上了大鸿沟全异步Agentic RL西宾,权臣擢升了它在搜索、编码这些长链条任务上的自主扩充才智,让它从单纯的“作念题家”造成了能信得过下场干活的实战派。
Ring-2.5-1T实战演练接下来把Ring拉出来遛遛,我让Gemini成心运筹帷幄了全部能把东说念主脑干烧的综合代数讲明题。
这说念题目磨真金不怕火的是群论,要求模子在一个有限群里讲明非交换群的阶≥27,还得把中心阶和正规子群的底细给摸清。
Ring-2.5-1T接招的姿势亦然异常专科。它先是反手掏出Cauchy定理,接着就运转丝丝入扣地排雷,把阶为1、3、9这些只然而交换群的坑全给躲避了。
况兼它在讲明非交换性的时候,不仅没被那种“3^k阶群细则交换”的直观给带偏,还顺利把Heisenberg群甩出来当反例,不错说很有逻辑明锐度了。
通盘实测看下来,它的逻辑推导严丝合缝。模子不仅把精湛定理给吃透了,在处理这种长达好几步的逻辑链条时还没出半点玩忽,绝顶是对反例的垄断顺利把它的逻辑深度拉满。
这足以讲明密集奖励西宾照实让模子长了脑子,它处理这类硬核逻辑任务时的发挥,十足是实战派的水准。
测收场硬核的数学艰辛,我们再来望望这个实战派选手在系统级编程上,到底稳不稳。
这说念代码实测题要求模子用Rust言语从零运转手写一个高并发线程池,模子得在无须任何现成库的情况下,靠Arc、Mutex和Condvar把任务分发逻辑给硬生生地搭出来。
不光得能跑,还得因循“优雅关机”,意念念即是干线程在退出的时侯,必须确保总共派发出去的活儿全干完,况兼坚定不行出现死锁这种初级诞妄。
另外还得加个监控模块,万一哪天某个Worker线程顺利崩溃了,模子得能自动发现并把线程重启,况兼还没处理完的任务部队一个王人不行丢,这异常考验模子对内存安全和并发底层的泄露。
来看Ring-2.5-1T给出的这份代码,它的处理形式照实异常成熟。它通过panic::catch_unwind精确拿获崩溃并互助一个独处的监控线程已毕自动重启,这种运筹帷幄玄妙躲避了入门者最容易掉进去的死锁陷坑。
代码在总共权治理与异步见知上的逻辑领会且成熟,优雅关机部分通度日动线程计数与信号量叫醒机制互助,竣工达成了任务全部清空的主义。
把长入模态作念成可复用底座
除了在架构和推理上的大当作,蚂鸠集团在通用东说念主工智能基模领域保抓多线并进,同期发布了扩散言语模子LLaDA2.1和全模态大模子Ming-flash-omni-2.0。
LLaDA2.1给与了非自转头并行解码工夫,透顶改动了传统模子逐词瞻望的生成范式,推理速率达到了535tokens/s,在特定任务(如 HumanEval+编程任务)上的费解量以致达到了更惊东说念主的892tokens/s。
这种架构不仅大幅擢升了费解成果,也让模子具备了私有的Token裁剪与逆向推理才智。它不错顺利在推理历程中对文本中间的特定Token进行精确修正,概况基于预设的范围条目进行反向逻辑记忆。
这种无邪性在处理需要高频改写或复杂逻辑回溯的任务时,展现出了比传统自转头模子更强的适配性。
全模态大模子Ming-flash-omni-2.0则是在视觉、音频、文本的长入表征与生成上已毕了重要突破。
它在工夫底层买通了视觉、音频与文本的范围,通过全模态感知的强化与泛音频长入生成框架,让模子既具备博学的众人级学问储备,又领有千里浸式的音画同步创作才智。
这种万能型架构,已毕了极高反映频率下的及时感官交互。
这一大波工夫更新背后的算盘很明晰,蚂蚁inclusionAI是想把这些才智作念成可复用底座。
这即是要给行业打个样,给建筑者提供一个长入的才智进口,以后想作念多模态应用无须再到处找模子勉强了,顺利调这个现成的底座就行。
据称照旧明牌的是,接下来团队还会持续死磕视频时序泄露、复杂图像裁剪和长音频及时生成这几个硬骨头。
这些其实王人是全模态工夫鸿沟化落地的临了几说念关卡,惟有把长视频逻辑看懂、把复杂修图搞精、把音频生成弄得更丝滑,全模态AI就能在各式干活场景里信得过爆发了。
蚂蚁这一套组合拳打下来,能嗅觉到他们在春节档这波华山论剑里真不是来凑烦闷的,这一册本结识的收获单交出来,顺利就把工夫底蕴给亮透了。
这种从底层逻辑到实战扩充的全面爆发,稳稳地讲明了他们即是全球AI圈子里最顶尖的那一拨选手,展现出了第一梯队的水平。
蚂蚁当今的路数,照旧跳出了单纯炫技的层面,他们正把这些压箱底的身手,造成世界能顺利上手的底座决策。
大模子的华山论剑,门槛被蚂蚁卷得更高了。
开源地址
GitHub:https://github.com/inclusionAI/Ring-V2.5Huggingface:https://huggingface.co/inclusionAI/Ring-2.5-1TModelScope:https://www.modelscope.cn/models/inclusionAI/Ring-2.5-1T— 完 —
量子位 QbitAI
心思我们开云体育(中国)官方网站,第一期间获知前沿科技动态


